1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
DROP TABLE IF EXISTS `employees3`;
CREATE TABLE `employees3` (
`eid` int(11) NOT NULL COMMENT '主键ID',
`ename` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '姓名',
`position` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '位置',
PRIMARY KEY (`eid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
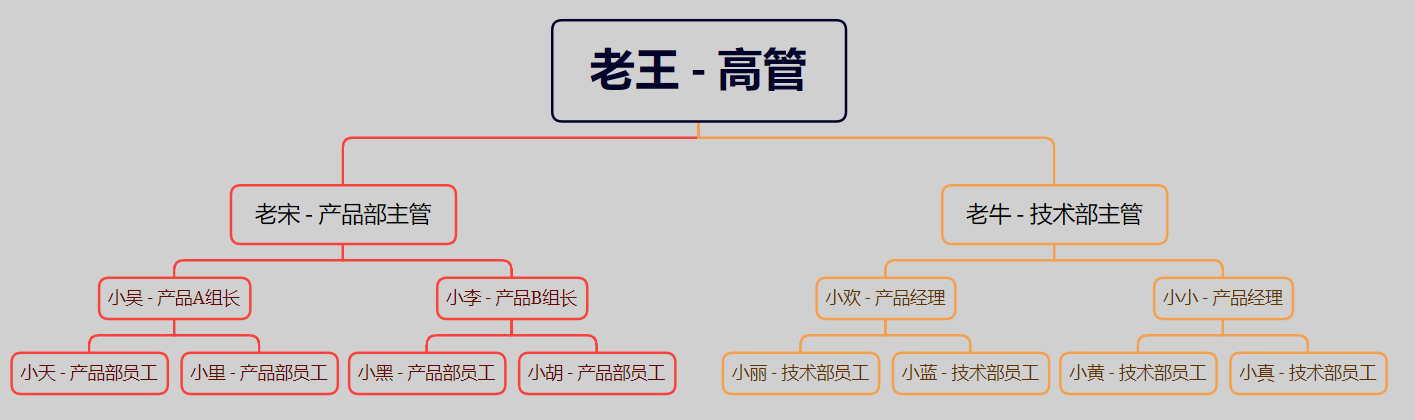
INSERT INTO `employees3` VALUES (1, '老王', '高管');
INSERT INTO `employees3` VALUES (2, '老宋', '产品部主管');
INSERT INTO `employees3` VALUES (3, '老牛', '技术部主管');
INSERT INTO `employees3` VALUES (4, '小吴', '产品A组长');
INSERT INTO `employees3` VALUES (5, '小李', '产品B组长');
INSERT INTO `employees3` VALUES (6, '小欢', '产品经理');
INSERT INTO `employees3` VALUES (7, '小小', '产品经理');
INSERT INTO `employees3` VALUES (8, '小天', '产品部员工');
INSERT INTO `employees3` VALUES (9, '小里', '产品部员工');
INSERT INTO `employees3` VALUES (10, '小黑', '产品部员工');
INSERT INTO `employees3` VALUES (11, '小胡', '产品部员工');
INSERT INTO `employees3` VALUES (12, '小丽', '技术部员工');
INSERT INTO `employees3` VALUES (13, '小蓝', '技术部员工');
INSERT INTO `employees3` VALUES (14, '小黄', '技术部员工');
INSERT INTO `employees3` VALUES (15, '小真', '技术部员工');
DROP TABLE IF EXISTS `emp_relations`;
CREATE TABLE `emp_relations` (
`root_id` int(11) NULL DEFAULT NULL COMMENT '根节点的eid',
`depth` int(11) NULL DEFAULT NULL COMMENT '根节点到该节点的深度',
`is_leaf` tinyint(1) NULL DEFAULT NULL COMMENT '该节点是否为叶子节点',
`node_id` int(11) NULL DEFAULT NULL COMMENT '该节点的eid'
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `emp_relations` VALUES (1, 0, 0, 1);
INSERT INTO `emp_relations` VALUES (1, 1, 0, 2);
INSERT INTO `emp_relations` VALUES (1, 1, 0, 3);
INSERT INTO `emp_relations` VALUES (1, 2, 0, 4);
INSERT INTO `emp_relations` VALUES (1, 2, 0, 5);
INSERT INTO `emp_relations` VALUES (1, 2, 0, 6);
INSERT INTO `emp_relations` VALUES (1, 2, 0, 7);
INSERT INTO `emp_relations` VALUES (1, 3, 1, 8);
INSERT INTO `emp_relations` VALUES (1, 3, 1, 9);
INSERT INTO `emp_relations` VALUES (1, 3, 1, 10);
INSERT INTO `emp_relations` VALUES (1, 3, 1, 11);
INSERT INTO `emp_relations` VALUES (1, 3, 1, 12);
INSERT INTO `emp_relations` VALUES (1, 3, 1, 13);
INSERT INTO `emp_relations` VALUES (1, 3, 1, 14);
INSERT INTO `emp_relations` VALUES (1, 3, 1, 15);
INSERT INTO `emp_relations` VALUES (2, 0, 0, 2);
INSERT INTO `emp_relations` VALUES (2, 1, 0, 4);
INSERT INTO `emp_relations` VALUES (2, 1, 0, 5);
INSERT INTO `emp_relations` VALUES (2, 2, 1, 8);
INSERT INTO `emp_relations` VALUES (2, 2, 1, 9);
INSERT INTO `emp_relations` VALUES (2, 2, 1, 0);
INSERT INTO `emp_relations` VALUES (2, 2, 1, 11);
INSERT INTO `emp_relations` VALUES (3, 0, 0, 3);
INSERT INTO `emp_relations` VALUES (3, 1, 0, 6);
INSERT INTO `emp_relations` VALUES (3, 1, 0, 7);
INSERT INTO `emp_relations` VALUES (3, 2, 1, 12);
INSERT INTO `emp_relations` VALUES (3, 2, 1, 13);
INSERT INTO `emp_relations` VALUES (3, 2, 1, 14);
INSERT INTO `emp_relations` VALUES (3, 2, 1, 15);
INSERT INTO `emp_relations` VALUES (4, 0, 0, 4);
INSERT INTO `emp_relations` VALUES (4, 1, 1, 8);
INSERT INTO `emp_relations` VALUES (4, 1, 1, 9);
INSERT INTO `emp_relations` VALUES (5, 0, 0, 5);
INSERT INTO `emp_relations` VALUES (5, 1, 1, 10);
INSERT INTO `emp_relations` VALUES (5, 1, 1, 11);
INSERT INTO `emp_relations` VALUES (5, 1, 1, 12);
|