
学成在线--项目优化
在此特别感谢黑马程序员提供的课程
写在最前
优化需求
- 视频播放页面,用户未登录也可以访问,当用户观看试学课程时,需要请求服务端查询数据,接口如下
- 根据课程id查询课程信息
- 根据文件id查询视频信息
- 这些接口在用户为仁恒状态下也可以访问,如果接口的性能不高,当高并发到来,很有可能会耗尽整个系统的资源,将整个系统压垮,所以我们需要对这些暴露在外边的接口进行优化
压力测试
性能指标
- 对接口进行优化之前,需要对接口进行压力测试,不仅接口需要压力测试,整个微服务在发布前也需要经历压力测试,因为压力测试可以暴露功能测试所发现不了的问题
- 功能测试即是对系统的功能按用户需求进行测试,例如:添加一门课程,根据需求文档先准备测试数据,在通过前端界面将一门课程添加到系统,测试是否可以操作成功。整个过程就是测试软件是否可以满足用户的需求
- 压力测试是通过测试工具制造大规模的并发请求去访问系统,测试系统是否经受得住压力
- 例如:一个学习网站,上线要求该网站可以支持1万用户同时在线,此时就需要模拟1万并发去访问网站的关键业务流程,例如:测试点播学习流程,测试系统是否可以抗住1万并发请求
- 一些功能测试时无法发现的问题,在压力测试时就会发现,例如:内存泄露、线程安全、IO异常等问题
- 压力测试常用的性能指标如下
吞吐量:吞吐量食指系统每秒可以处理的事务数,也成为了TPS(Transaction Per Second)- 例如:一次点播从请求进入系统,到视频图像显示出来,这整个流程就是一次事务
- 所以吞吐量并不是依次数据库事务,而是完成一次业务的整体流程
响应时间:响应时间是指客户端请求服务端,从请求进入系统到客户端拿到响应结果所经历的时间- 响应时间包括:最大响应时间、最小响应时间、平均响应时间
每秒查询数:每秒查询数即QPS(Queries Per Second),它是衡量查询接口的性能指标。- 例如:商品信息的查询,疫苗可以请求该接口查询商品信息的次数就是QPS
- 拿查询接口举例,依次查询请求内部不会再去请求其它接口,此时QPS = TPS
- 如果一次查询请求内部需要调用另一个接口查询数据,此时QPS = 2 × TPS
错误率:错误率是指一批请求发生错误的请求站全部请求的比例
- 不同的指标其要求不同,例如现在进行接口优化,优化后的接口响应时间应该越来越小,吞吐量越来越大,以及QPS值爷是越大越好,错误率要保持在一个很小的范围
- 另外除了关注这些性能指标以外,还要关注系统的负载情况
- CPU使用率:不高于85%
- 内存利用率:不高于85%
- 网络利用率:不高于80%
- 磁盘ID:磁盘IO的性能指标是IOPS(Input/Output Per Second),即每秒的输入输出量(或读写次数)
- 如果过大,说明操作太密集,IO过大也会影响性能指标
安装Jmeter
- 链接:https://jmeter.apache.org/download_jmeter.cgi
- 下载安装,进入bin目录,以管理员身份运行jmeter.bat
压力测试
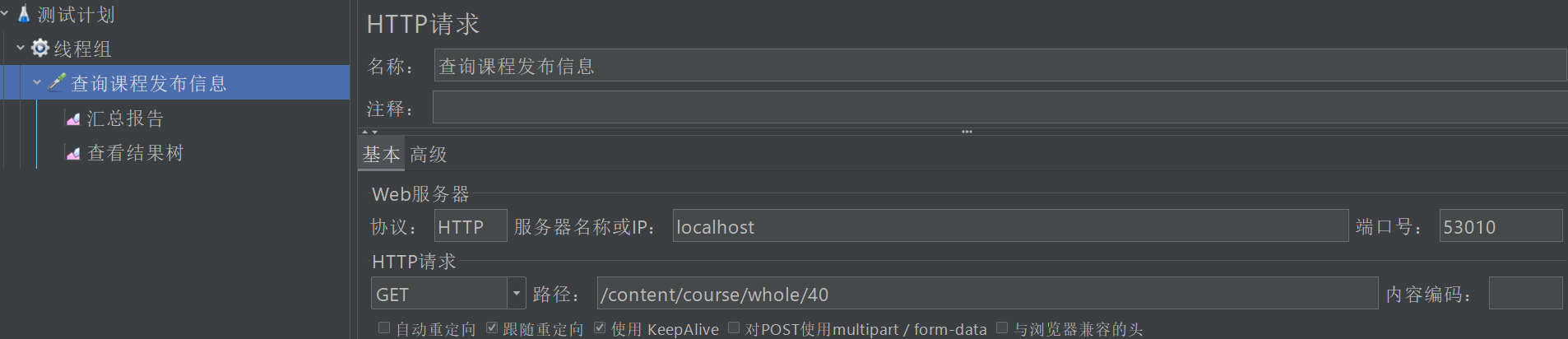
- 200个线程,每个线程请求100次,共计20000次,通过网关访问

- 查询课程发布信息,吞吐量在450左右
https://s1.ax1x.com/2023/03/25/ppDk4KI.png
优化日志
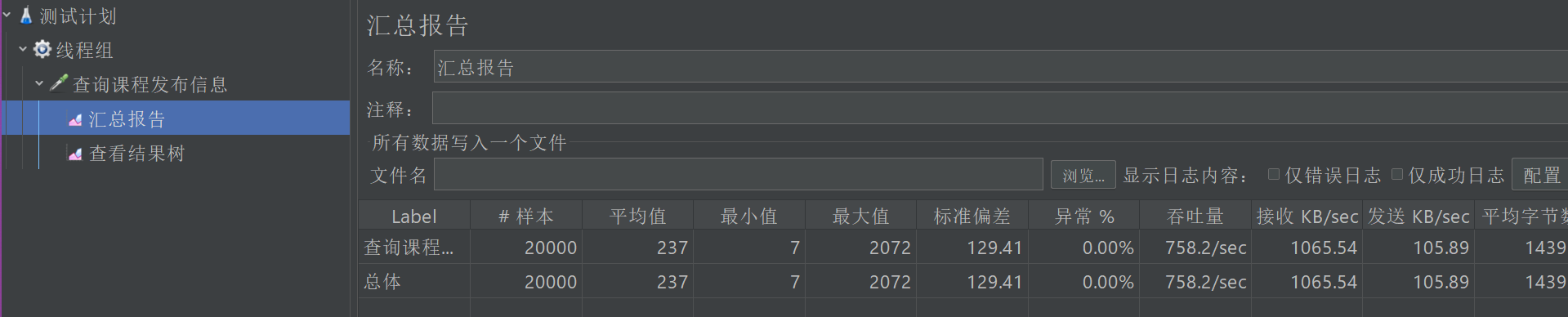
- 将内容管理模块的日志级别改为INFO,再次测试,吞吐量达到了750
缓存优化
Redis缓存
- 测试用例是根据id查询课程信息,这里不存在复杂的SQL,也不存在数据库连接不释放的问题,暂时不考虑数据库方面的优化。
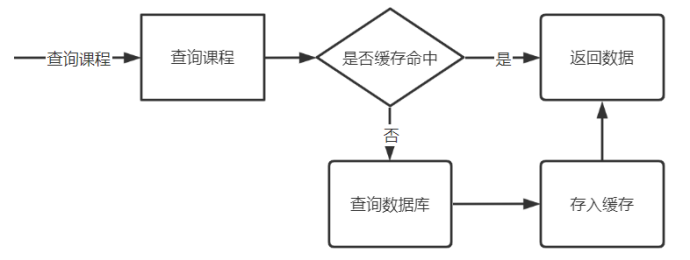
- 课程发布信息的特点是查询较多,修改很少,所以这里可以考虑将课程发布信息缓存到Redis,每次查询课程先从Redis中查询
- 如果Redis中有课程发布信息,则直接返回
- 如果Redis中没有课程发布信息,则再查询数据库,同时将查询到的课程发布信息存入Redis,然后返回数据
- 在nacos中配置redis-dev.yaml
1 | spring: |
- 在content-api中加载redis-dev.yaml
1 | - data-id: feign-${spring.profiles.active}.yaml |
- 在content-service中添加依赖
1 | <dependency> |
- 定义查询缓存接口
1 | /** |
- 接口实现如下
1 |
|
- 由于我们现在是第一次使用Redis缓存,所以我们先用HttpClient进行测试,看看日志是否会输出
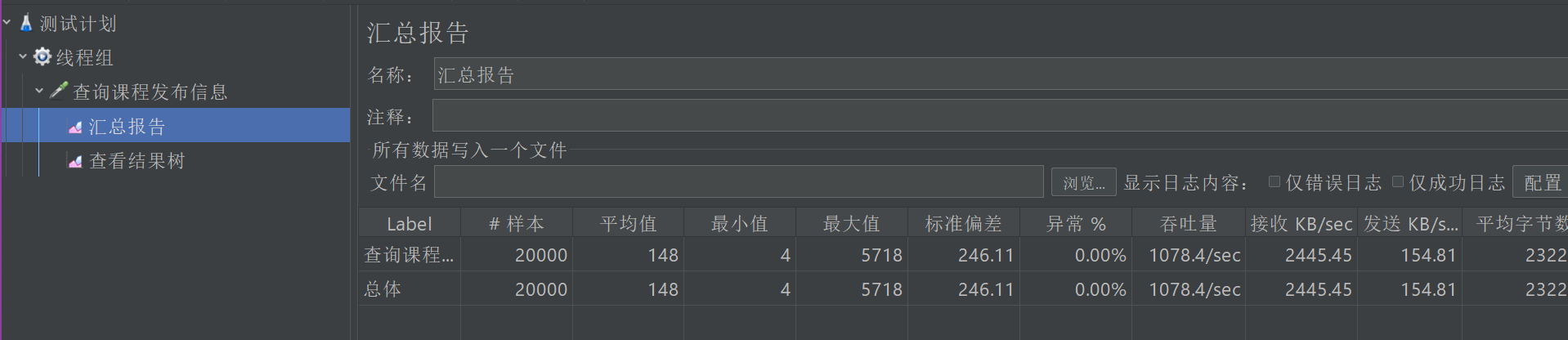
缓存中没有.. - 然后使用Jmeter进行测试,吞吐量在1100附近(我这里还起了一台虚拟机,性能稍有下降)
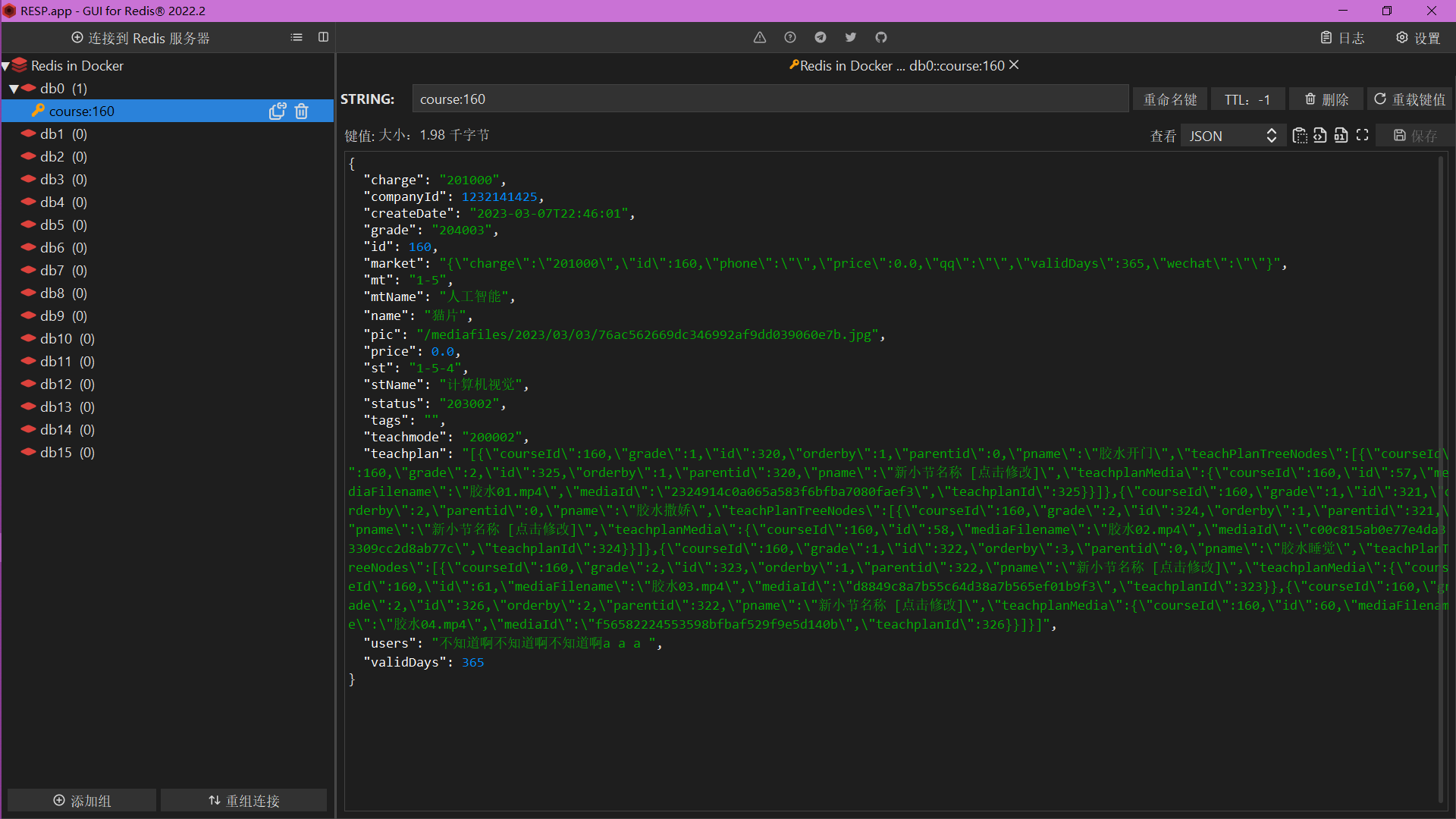
- Redis图形化界面中也可以看到我们的缓存数据
缓存穿透问题
什么是缓存穿透
- 使用缓存后,代码的性能有了很大的提升,但是控制台还是打出了很多从数据库查询的日志,明明已经判断了如果缓存存在,课程信息就从缓存中查询,那为什么还有这么多从数据库查询的请求呢?
- 因为并发数很高,很多线程会同时到达查询数据库代码处去执行
- 如果存在恶意攻击的可能,大量并发去查询一个不存在的课程信息会出现什么问题呢?
- 例如去请求一门不存在的课程,进行压力测试时会发现一直在请求数据库
- 大量并发去访问一个数据库不存在的数据,由于缓存中没有该数据,就会导致大量并发查询数据库,这个现象叫缓存穿透
- 缓存穿透可以造成数据库瞬间压力过大,连接数等资源耗尽,最终数据库拒绝连接,不可用
解决缓存穿透
- 如何解决缓存穿透?
- 对请求增加校验极致
例如:课程ID是Long类型,如果发来的不是Long类型直接返回NULL - 使用布隆过滤器
布隆过滤器可以用于检索一个元素是否在一个集合中。如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
布隆过滤器的特点是,高效地插入和查询,占用空间少;查询结果有不确定性,如果查询结果是存在则元素不一定存在,如果不存在则一定不存在;另外它只能添加元素不能删除元素,因为删除元素会增加误判率。
比如:将商品id写入布隆过滤器,如果分3次hash此时在布隆过滤器有3个点,当从布隆过滤器查询该商品id,通过hash找到了该商品id在过滤器中的点,此时返回1,如果找不到一定会返回0。
所以,为了避免缓存穿透我们需要缓存预热将要查询的课程或商品信息的id提前存入布隆过滤器,添加数据时将信息的id也存入过滤器,当去查询一个数据时先在布隆过滤器中找一下如果没有到到就说明不存在,此时直接返回。
实现方法有:
Google工具包Guava实现
Redisson - 缓存空值或特殊值
- 请求通过了第一步校验,查询数据库得到的数据不存在,此时我们仍然去缓存数据,缓存一个空值或一个特殊值的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27@Override
public CoursePublish getCoursePublishCache(Long courseId) {
// 1. 先从缓存中查询
String courseCacheJson = redisTemplate.opsForValue().get("course:" + courseId);
// 2. 如果缓存里有,直接返回
if (StringUtils.isNotEmpty(courseCacheJson)) {
log.debug("从缓存中查询");
+ if ("null".equals(courseCacheJson)) {
+ return null;
+ }
CoursePublish coursePublish = JSON.parseObject(courseCacheJson, CoursePublish.class);
return coursePublish;
} else {
log.debug("缓存中没有,查询数据库");
// 3. 如果缓存里没有,查询数据库
CoursePublish coursePublish = coursePublishMapper.selectById(courseId);
+ if (coursePublish == null) {
+ redisTemplate.opsForValue().set("course:" + courseId, "null", 30, TimeUnit.SECONDS);
+ return null;
+ }
String jsonString = JSON.toJSONString(coursePublish);
// 3.1 将查询结果缓存
redisTemplate.opsForValue().set("course:" + courseId, jsonString);
// 3.1 返回查询结果
return coursePublish;
}
}
- 对请求增加校验极致
缓存雪崩
什么是缓存雪崩
- 缓存雪崩是缓存中大量key失效后,当高并发到来时导致大量请求到数据库,瞬间耗尽数据库资源,导致数据库无法使用
- 造成缓存雪崩问题的原因是大量key拥有了相同的过期时间
- 例如:对课程信息设置缓存过期时间为10分钟,当大量请求同时查询大量课程信息时,由于大量课程拥有相同的过期时间,所以大量课程的缓存信息也会同时失效,出现缓存雪崩问题
解决缓存雪崩
- 如何解决缓存雪崩?
- 使用同步锁控制数据库的线程
- 使用同步锁控制查询数据库的线程,只允许有一个线程去查询数据库,查询得到数据后存入缓存
1
2
3
4
5synchronized(obj) {
// 1. 查询数据库
// 2. 写入缓存
} - 对同一类型信息的key设置不同的过期时间
- 通常对一类信息的key设置的过期时间是相同的,这里可以在原有的固定时间基础上,加上一个随机时间,从而使他们的过期时间不相同
1
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(null), 30 + new Random().nextInt(100), TimeUnit.SECONDS);
- 缓存预热
- 不用等到请求到来再去查询数据库存入缓存,可以写一个定时任务,提前将数据存入缓存。使用缓存预热机制,通常有专门的后台程序去讲数据库的数据同步到华奴才能
- 使用同步锁控制数据库的线程
缓存击穿
什么是缓存击穿
- 缓存击穿是指大量并发访问同一个热点数据,当人丹数据失效后,同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用
- 例如:某手机新品发布,此时手机数据存在缓存中,如果在秒杀的时候,缓存刚好失效,那么此时就会有大量请求直接访问数据库
解决缓存击穿
- 如何解决缓存击穿?
- 使用同步锁控制查询数据库的线程,只允许有一个线程去查询数据库,查询得到的数据存入缓存
1
2
3
4
5synchronized(obj) {
// 1. 查询数据库
// 2. 写入缓存
}- 热点数据不过期
- 可以由后台程序提前将热点数据加入缓存,缓存时间设置不过期,由后台程序做好缓存同步
- 下面使用synchronized对代码加锁
1 | @Override |
- 测试吞吐量,不到700
- 对上面的代码进行优化,由于我们是将整个方法都加上了锁,就导致我们查询缓存时,也是单线程
- 我们加锁的时候,要尽可能缩小锁的范围,我们只需要在查询数据库的时候加锁,修改代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public CoursePublish getCoursePublishCache(Long courseId) {
// 1. 先从缓存中查询
String courseCacheJson = redisTemplate.opsForValue().get("course:" + courseId);
// 2. 如果缓存里有,直接返回
if (StringUtils.isNotEmpty(courseCacheJson)) {
log.debug("从缓存中查询");
if ("null".equals(courseCacheJson)) {
return null;
}
CoursePublish coursePublish = JSON.parseObject(courseCacheJson, CoursePublish.class);
return coursePublish;
} else {
synchronized (this) {
// double check
courseCacheJson = redisTemplate.opsForValue().get("course:" + courseId);
if (StringUtils.isNotEmpty(courseCacheJson)) {
log.debug("从缓存中查询");
if ("null".equals(courseCacheJson)) {
return null;
}
CoursePublish coursePublish = JSON.parseObject(courseCacheJson, CoursePublish.class);
return coursePublish;
}
log.debug("缓存中没有,查询数据库");
// 3. 如果缓存里没有,查询数据库
CoursePublish coursePublish = coursePublishMapper.selectById(courseId);
if (coursePublish == null) {
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(null), 30 + new Random().nextInt(100), TimeUnit.SECONDS);
return null;
}
String jsonString = JSON.toJSONString(coursePublish);
// 3.1 将查询结果缓存
redisTemplate.opsForValue().set("course:" + courseId, jsonString, 300 + new Random().nextInt(100), TimeUnit.SECONDS);
// 3.1 返回查询结果
return coursePublish;
}
}
}- 测试吞吐量,达到了1140,差不多是之前的二倍
小结
- 缓存穿透
- 去访问一个数据库不存在的数据,无法将数据进行缓存,导致直接查询数据库,当并发较大时,就会对数据库产生压力。
- 缓存穿透可以造成数据库压力增大,连接数等资源用完,最终数据库拒绝连接不可用
- 解决方案
- 缓存一个null值
- 布隆过滤器
- 缓存雪崩
- 缓存中大量key失效后,当高并发到来时,导致大量请求到数据库,瞬间耗尽数据库资源,导致数据库无法使用
- 造成缓存雪崩问题的原因是大量key拥有了相同的过期时间
- 解决方案:
- 使用同步锁控制
- 设置不同的过期时间,例如:使用固定数+随机数作为过期时间
- 缓存击穿
- 大量并发访问同一个热点数据,当热点数据失效后,同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用
- 解决方案
- 使用同步锁控制
- 设置key永不过期
分布式锁
本地锁的问题
- 上面的程序中使用了同步锁来解决缓存击穿、缓存雪崩的问题,保证同一个key过期后,只会查询一次数据库
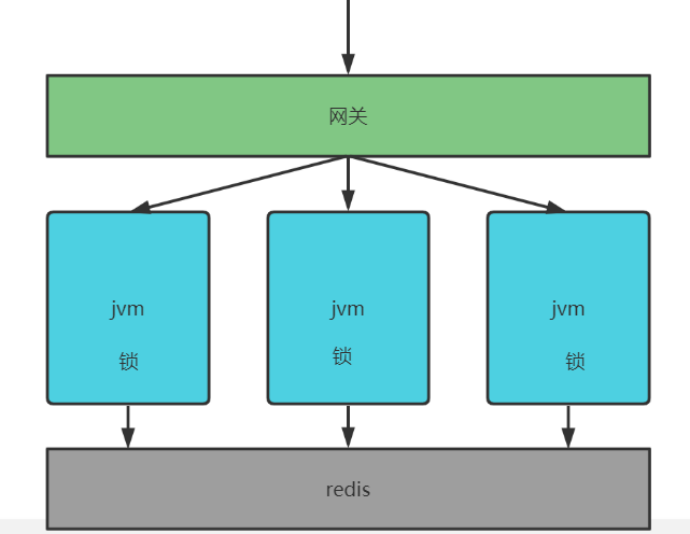
- 但如果将同步锁的程序,分布式部署在多个jvm上,则无法保证同一个key只会查询一次数据库
- 一个同步锁程序只能保证同一个jvm在多个线程只有一个线程去访问数据库
- 但如果高并发通过网关负载均衡转发给各个虚拟机,此时就会存在多个线程去查询数据库
- 因为jvm中的锁只能保证该虚拟机自己的线程去同步执行,无法跨jvm保证同步执行
- 下面我们进行测试,启动三个内容管理服务,注意要事先在nacos中的配置设置本地优先,然后复制配置,添加VM参数
-Dserver.port=53041
1 | spring: |
- 通过网关访问课程查询,网关通过负载均衡将请求转发给三个服务
- 测试发现,三个服务各有一次查询数据库,这说明本地锁无法跨JVM保证同步执行
什么是分布式锁
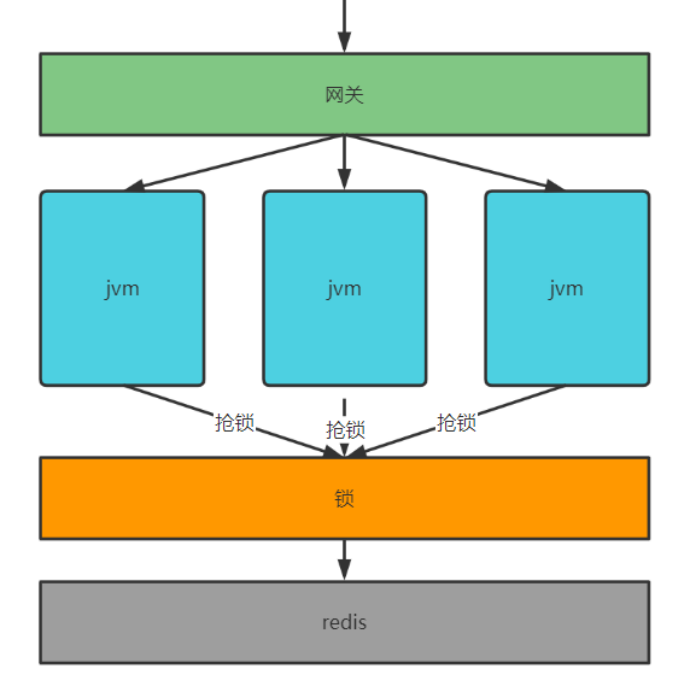
- 本地锁只能控制所在JVM中的线程同步执行,现在要实现分布式环境下所有虚拟机中的线程去同步执行,就需要让多个JVM使用同一把锁,JVM可以分布式部署,锁也可以分布式部署
- JVM去抢同一把锁,锁是一个单独的程序,提供加锁、解锁服务,谁抢到锁谁就去查询数据库
- 该锁不属于某个虚拟机,而是分布式部署,由多个虚拟机共享,这种锁叫分布式锁
分布式锁的实现方案
- 实现分布式锁的方案很多,常用的如下
- 基于数据库实现分布式锁
- 利用数据库主键唯一的特性,或利用数据库唯一索引的特点,多个县城同时去插入相同的记录,谁插入成功谁就抢到锁
- 基于Redis实现分布式锁
- Redis提供了分布式锁的实现方案,例如:SETNX、Redisson等
- 拿SETNX举例,SETNX是set一个不存在的key(set if not exists),多个线程去设置同一个key,只会有一个线程设置成功,设置成功的线程拿到锁
- 使用zookeeper实现
- zookeeper是一个分布式协调事务,主要解决分布式程序之间的同步问题
- zookeeper的结构类似文件目录,多线程向zookeeper创建一个子目录(节点)只会有一个创建成功,可以利用此特点实现分布式锁,谁创建该节点成功,谁就获得锁
- 基于数据库实现分布式锁
SETNX实现分布式锁
- 首先启动三个ssh客户端,连接redis
1 | docker exec -it redis redis-cli |
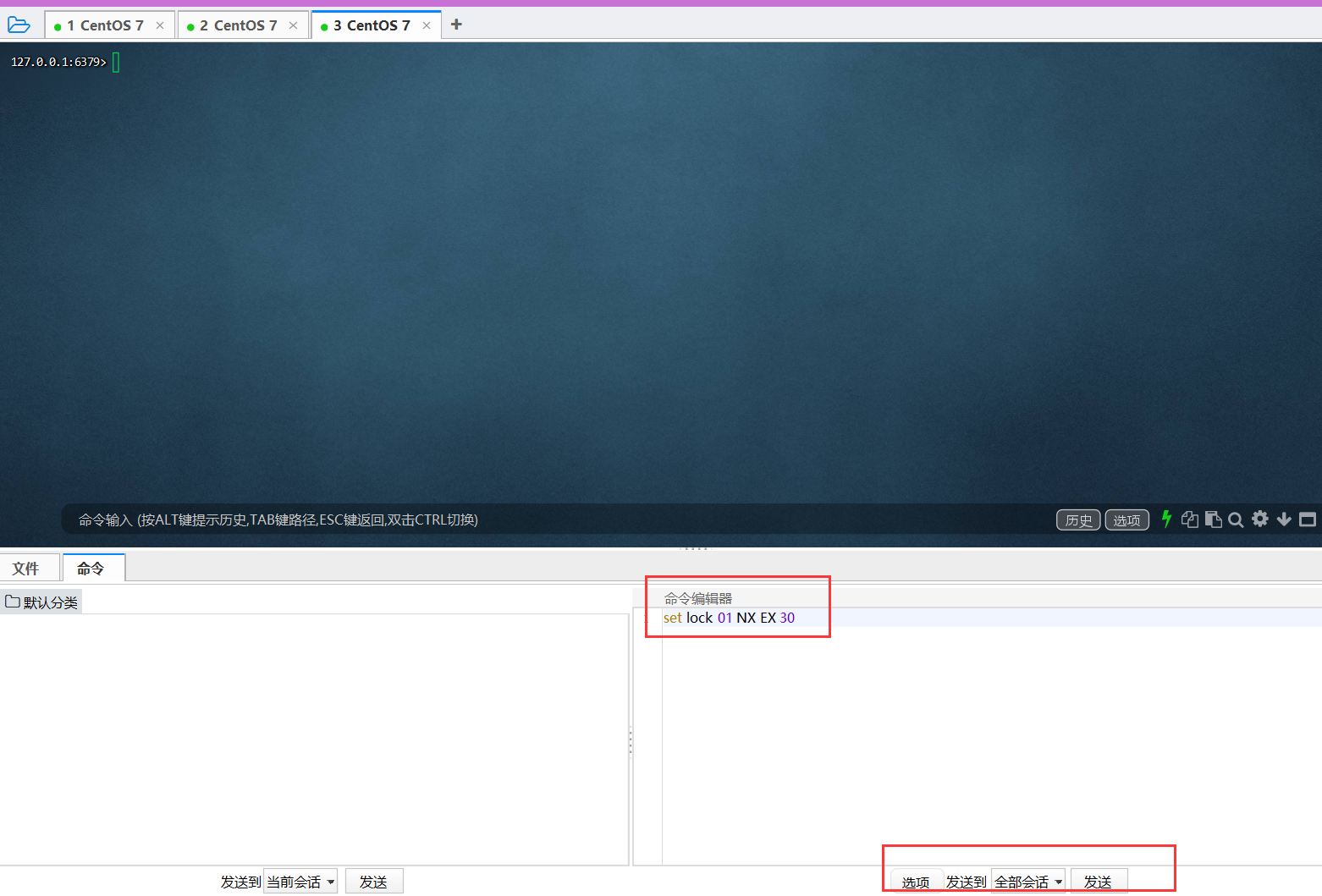
- 然后同时向三个客户端发送测试命令
1 | SET lock 01 NX EX 30 |
- 命令发送成功,观察ssh客户端
- 只有一个设置成功,返回ok
- 其余两个设置失败,返回nil
- 设置成功的请求表示抢到了lock锁,拿到锁的JVM就可以去操作数据库了
- 下面是在Java代码中使用SETNX实现分布式锁
1 | if(缓存中有) { |
- 下面我们来考虑几个问题
- 当SETNX一个key/value成功后,这个key(就是锁)需要设置过期时间吗?
- 如果不设置过期时间,当获取到了锁,却没有执行finally的话,这个锁会一直存在,其他线程无法获取这个锁
- 所以执行SETNX时要指定过期时间
- 如何释放锁
- 释放锁分为两种情况
- key到期自动释放
- 因为锁设置了过期时间,key到期会自动释放,但是会存在一个问题:查询数据库时,还没操作完,key就到期了
- 由于key到期了,就会导致其他线程也拿到了锁,最终重复查询数据库,执行了重复的业务操作
- 怎么解决这个问题?可以将key的到期时间设置的长一些,足以完成查询数据库并设置缓存等相关操作。但是这个效率会低一些,而且到期时间也不好把握
- 手动删除锁
- 如果是采用手动删除锁,可能和key到期自动删除有冲突,造成删除了别人的锁
- 例如:查询数据库等业务还没执行完,此时key过期了,别的线程又拿到锁进来了,当上一个线程执行完查询数据库业务之后,手动删除锁,把新进来的线程的锁给删了
- 要解决这个问题,可以在删除锁之前,判断这个锁是不是自己的,伪代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if (缓存中有) {
返回缓存中的数据
} else {
获取分布式锁:
set lock 01 NX
if (获取锁成功){
try {
查询数据库
} finally {
if (redis.call("get", "lock") == "01") {
释放锁:
redis.call("del", "lock")
}
}
}
}- 上述代码10~13行非原子性,也会导致删除其他线程的锁
- 想实现原子性,需要让redis去执行Lua脚本的方式去实现,这样就具有原子性,但是过期时间的值设置还存在不精准的问题
- key到期自动释放
- 释放锁分为两种情况
Redisson实现分布式锁
- 添加Redisson依赖
1 | <dependency> |
- 在redis配置文件中添加
1 | spring: |
- 同是也需要在content-service的resource目录下新增配置文件
1 |
|
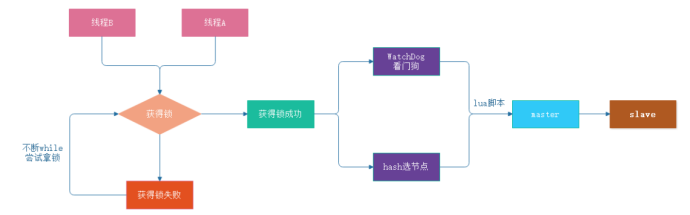
- Redisson相比SETNX实现分布式锁要简单的多,其工作原理如下
- 加锁机制
- 线程去获取锁,获取成功:执行lua脚本,保存数据到redis
- 线程去获取锁,获取失败:一致通过while循环常事获取锁,获取成功后,执行lua脚本,保存数据到redis
- WatchDog自动延期
- 第一种情况:在一个分布式环境下,假如一个线程获得锁后,突然服务器宕机了,那么这个时候在一定时间后这个锁会自动释放,你也可以设置锁的有效时间(当不设置默认30秒时),这样的目的主要是防止死锁的发生
- 第二种情况:线程A业务还没有执行完,时间就过了,线程A 还想持有锁的话,就会启动一个watch dog后台线程,不断的延长锁key的生存时间。
- Lua脚本保证原子性操作
- 主要是如果你的业务逻辑复杂的话,通过封装在lua脚本中发送给redis,而且redis是单线程的,这样就保证这段复杂业务逻辑执行的原子性
- 具体使用RLock操作分布式锁,RLock继承了JDK的Lock接口,所以他有Lock接口的所有特性,例如:lock、unlock、tryLock等特性,同时它还有很多新特性:强制锁释放、带有效期的锁
1 | public interface RRLock { |
- 使用分布式锁避免缓存击穿
1 | @Autowired |
- 启动多个内容管理服务示例,使用JMeter压力测试,只有一个实例查询一次数据库
- 测试Redisson自动续期功能,在查询数据库处添加休眠,在Redis图形化界面中查看锁的TTL是否会自动续期
1 | try { |
评论





